Secure Federated Learning Models Against Adversarial Attacks in Distributed Environments
Keywords:
Abstract
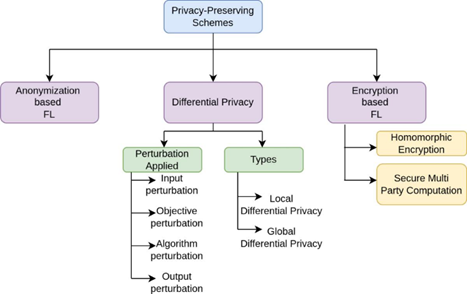
Federated Learning (FL) has emerged as a powerful distributed machine learning paradigm that enables multiple clients to collaboratively train a global model without sharing raw data, thereby preserving privacy in distributed environments. However, FL systems are highly vulnerable to adversarial attacks such as data poisoning, model poisoning, backdoor attacks, and inference attacks, which can severely degrade model performance and compromise system integrity. This research proposes a Secure Federated Learning Framework Against Adversarial Attacks in Distributed Environments, designed to enhance robustness, privacy, and trustworthiness in decentralized learning systems. The framework integrates adversarial detection mechanisms, secure aggregation protocols, anomaly-aware client selection, and robust optimization techniques to mitigate malicious behaviour during training. The proposed model employs robust aggregation strategies such as trimmed mean, median-based aggregation, and trust-weighted federated averaging to reduce the influence of poisoned updates. Additionally, a reinforcement learning-based anomaly detection module is introduced to identify malicious clients based on update behavior patterns. Differential privacy mechanisms and cryptographic secure aggregation further enhance data confidentiality. Experimental evaluation demonstrates that the proposed framework significantly improves model robustness under various adversarial attack scenarios while maintaining high accuracy and convergence stability. The system shows strong resilience against poisoning rates and reduces attack success probability compared to conventional federated learning approaches. The study contributes a scalable and secure federated learning architecture suitable for real-world applications in healthcare, IoT, autonomous systems, and edge intelligence environments where privacy and security are critical.