Vision Transformer Models for Deepfake Detection and Multimedia Authentication
Keywords:
Abstract
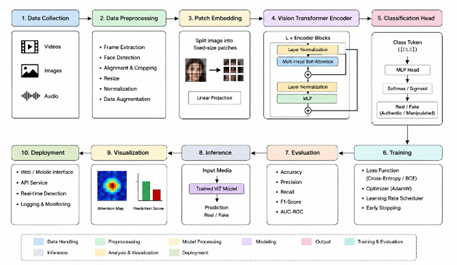
The rapid advancement of Artificial Intelligence (AI), deep learning, and generative multimedia technologies has significantly increased the creation and distribution of deepfake images, videos, and synthetic multimedia content across digital platforms. Deepfake technologies utilize sophisticated neural networks and generative adversarial models to manipulate facial expressions, voice patterns, and visual content, making forged multimedia appear highly realistic and difficult to distinguish from authentic data. Although deepfake systems offer beneficial applications in entertainment, education, virtual reality, and digital media generation, they also introduce severe cybersecurity, privacy, and misinformation challenges. Malicious deepfake content can be utilized for identity theft, political misinformation, financial fraud, cyber deception, social manipulation, and unauthorized multimedia tampering. Traditional multimedia authentication and forgery detection systems often struggle to identify modern deepfake manipulations due to increasingly sophisticated generative techniques and complex multimedia transformations. To address these challenges, this research proposes Vision Transformer (ViT)-Based Deepfake Detection and Multimedia Authentication Frameworks that integrate transformer-based deep learning architectures, intelligent feature extraction, multimedia integrity analysis, and adaptive classification mechanisms into a unified authentication system. The proposed framework utilizes Vision Transformer models to analyze spatial relationships, global visual dependencies, and semantic inconsistencies within multimedia content for accurate deepfake identification. The architecture integrates image preprocessing, patch embedding, self-attention mechanisms, feature learning, and multimedia authentication modules to improve forgery detection capability and reduce false-positive classifications. Furthermore, the framework incorporates adaptive learning and real-time multimedia verification mechanisms for detecting manipulated videos, synthetic facial images, forged speech-video synchronization, and AI-generated content. Experimental evaluation demonstrates that the proposed Vision Transformer-based framework significantly improves deepfake detection accuracy, multimedia authentication reliability, attack resistance, and real-time processing efficiency compared with traditional convolutional neural network-based systems. The proposed architecture establishes a robust and intelligent multimedia authentication framework suitable for combating AI-generated misinformation and securing next-generation digital communication environments.