
Deep Fake Audio Recognition Using Deep Learning
DOI:
https://doi.org/10.65521/intjournalrecadvengtech.v14i1.198Keywords:
Abstract
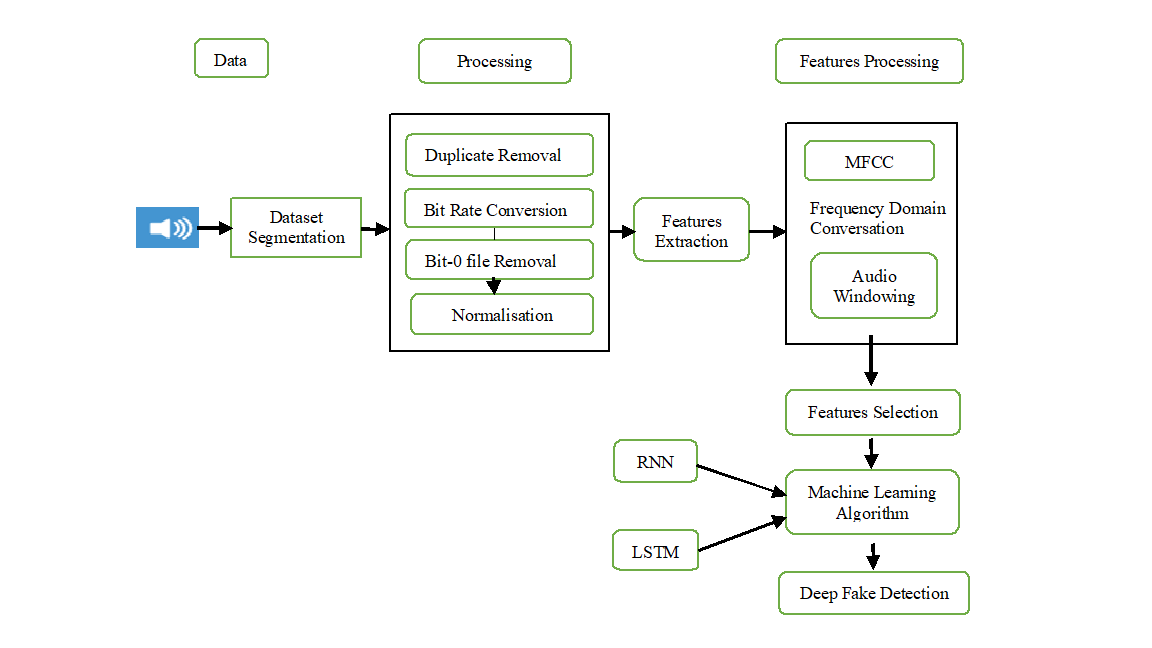
The development of deep learning algorithms in recent years has made it possible to produce deep fake audio, which is extremely lifelike synthetic audio. Security, privacy, and the legitimacy of digital communications are all seriously jeopardized by this. The goal of this research is to use Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks to create a reliable deep fake audio detection system. Mel-frequency cepstral coefficients (MFCCs) and spectrograms are two sophisticated audio feature extraction techniques that the suggested system uses to reliably differentiate between real and artificial sounds. To ensure their efficacy in real-world situations, the RNN and LSTM-based models are trained and assessed on a variety of datasets of deep fake and true audio samples. This study emphasizes how crucial deep fake audio detection is to protecting privacy, upholding digital communications' credibility, and guaranteeing the accuracy of audio evidence in court.
Downloads
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.