Federated Multimodal Language Recognition: A Deep Learning Approach for Real-Time Applications
Article Sidebar
Main Article Content
Abstract
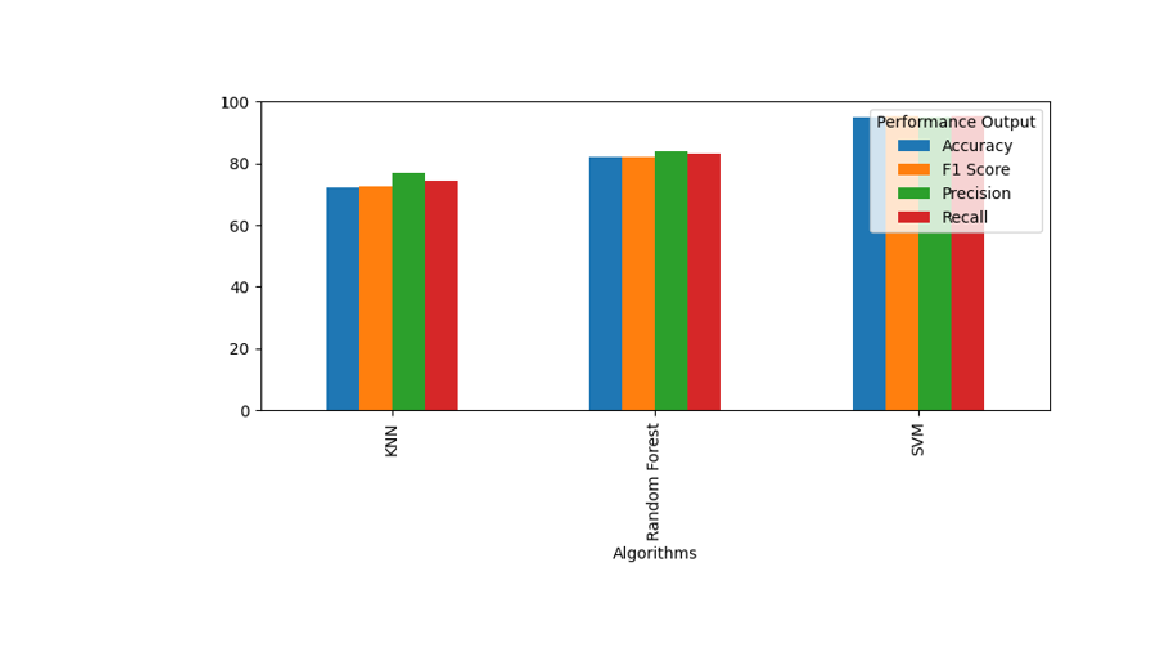
In a world of growing linguistic diversity, multilingual identification systems are essential for seamless communication across digital platforms and real-world applications. This research presents a robust, deep learning-based multilingual identification framework capable of recognizing and translating languages from text, speech, and image modalities. The proposed system integrates machine learning classifiers—Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Random Forest—with N-gram-based feature extraction to build baseline models. Experimental results highlight SVM's superior performance, achieving 95% accuracy across Tamil, Hindi, and Marathi languages. In parallel, the framework extends to real-time multilingual detection by incorporating advanced deep learning techniques such as Transformers, YOLOv5, and Whisper AI for hybrid text, speech, and image inputs.A key innovation in the system is the integration of Federated Learning (FL), enabling decentralized model training while preserving user privacy. This enhances both scalability and security, particularly in applications such as missing child identification, multilingual surveillance, and cross-border intelligence analysis. The system also features a translation module using Google Translator to convert recognized languages into English, making outputs more accessible for non-native speakers. Evaluations conducted across benchmark datasets demonstrate high precision, recall, and low latency, affirming the system's potential for real-world deployment. Future enhancements will explore large-scale multilingual datasets, context-aware neural architectures, and further FL optimization for real-time, privacy-preserving language recognition.
Downloads
Article Details

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.