
Text Summarization for Marathi Text documents using TextRank Algorithm
DOI:
https://doi.org/10.65521/ijacte.v15i1S.1321Keywords:
Abstract
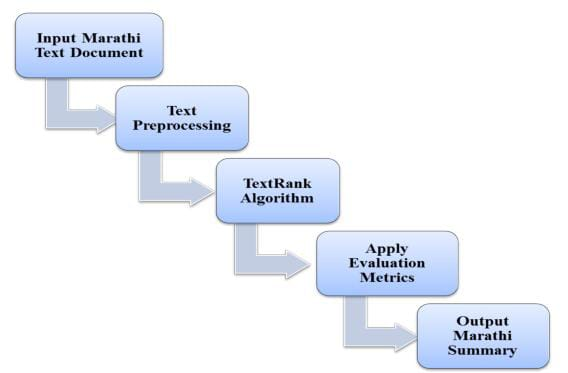
In today’s digital world, the massive growth of information has created an urgent need for automatic tools that can condense lengthy documents into concise and meaningful summaries. Text summarization has emerged as an important research area to address this challenge, helping readers quickly understand the essence of large texts. While much progress has been made in English and other global languages, Indian languages such as Marathi still lack sufficient resources and research in this field. Marathi, being one of the most widely spoken languages in India, is used extensively in government communication, especially in legal and administrative documents. These legal documents are often lengthy, complex, and filled with formal language, making it difficult for readers to extract key information efficiently. To address this issue, we apply the TextRank algorithm, a graph-based ranking method, for automatic summarization of Marathi legal documents. The proposed system selects the most important sentences to create a concise extractive summary that preserves the original meaning. Experimental results show that this approach significantly reduces the length of the document while retaining critical information, thereby improving the accessibility and usability of legal texts.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.