
Privacy-Preserving Document Intelligence System using OCR, LexRank, and Local LLMs
DOI:
https://doi.org/10.65521/intjournalrecadvengtech.v15i1.2063Keywords:
Abstract
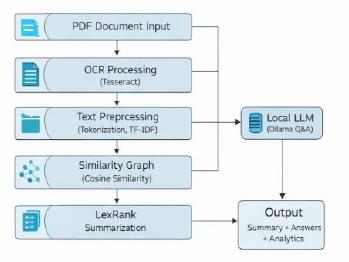
The rapid proliferation of digital documents has led to a growing need for systems capable of handling scanned and image-based Portable Document Format (PDF) files, which often lack machine-readable text and are difficult to search, analyze, and interact with. Existing solutions are typically based on cloud computing or computationally intensive transformer architectures, raising concerns about data privacy and resource consumption. This paper proposes a fully local and privacy- conscious document intelligence system that integrates Optical Character Recognition (OCR), extractive summarization, and question answering. Text extraction is performed using Tesseract OCR, followed by TF-IDF vectorization, cosine similarity, and graph-based processing. The LexRank algorithm is employed to generate concise summaries, while a locally deployed Large Language Model enables document-based question answering. Additionally, the system provides document analytics, such as word count and reading time has been implemented using Streamlit. The proposed system ensures efficiency, security, and offline processing, making it suitable for private and sensitive applications.
Downloads
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.