A Tri-Modal Deepfake Forensics and Web Interception Architecture
DOI:
https://doi.org/10.65521/ijeecs.v15i1S.3069Keywords:
Abstract
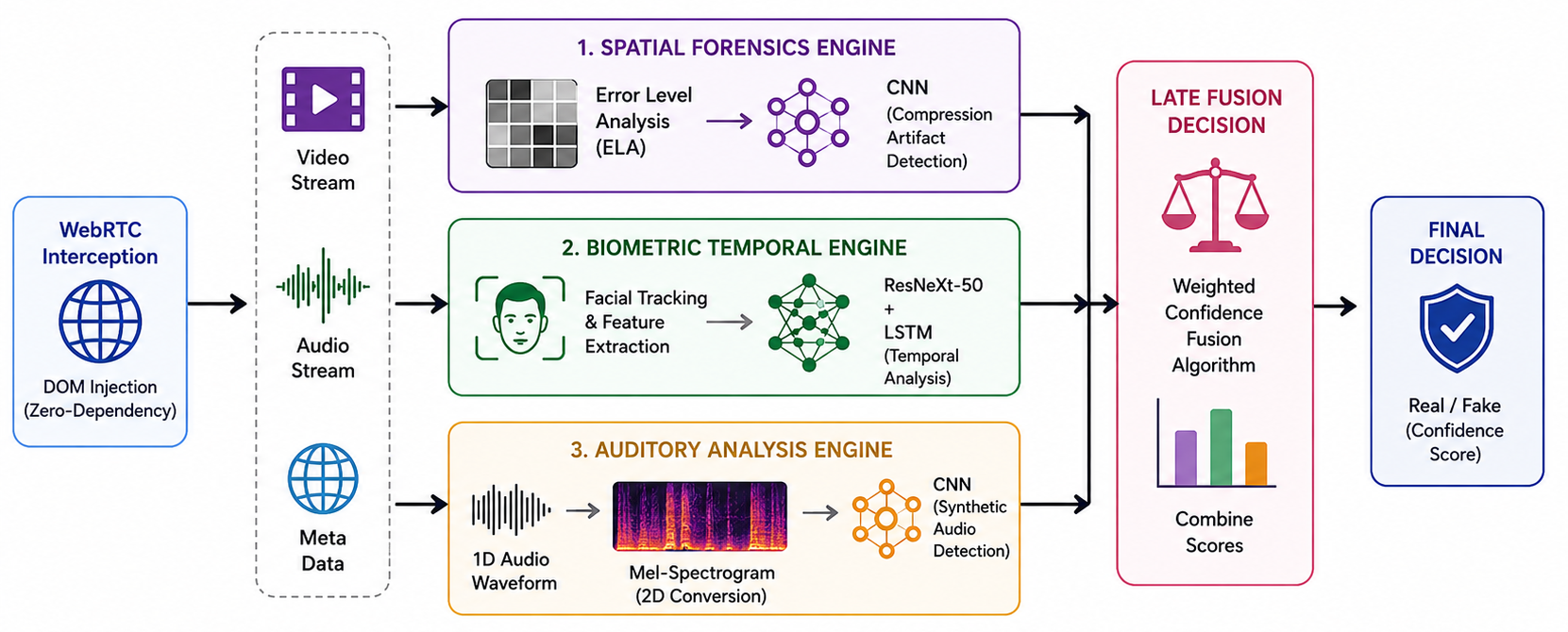
The rapid proliferation of highly realistic synthetic media, commonly known as deepfakes, poses a severe threat to digital identity verification and media authenticity. Current deepfake detection methodologies predominantly rely on single-modality neural networks or computationally prohibitive feature-level fusion, rendering them inefficient for real-time web deployment. This paper surveys existing unimodal and multimodal deepfake detection frameworks and proposes a novel, highly scalable alternative: a decoupled, Tri-Modal Late-Fusion architecture. The proposed system evaluates media through three parallel, asynchronous pipelines: a Spatial engine utilizing Error Level Analysis (ELA) paired with a Convolutional Neural Network (CNN) for compression artifact detection; a Biometric engine employing a ResNeXt-50 and LSTM network for temporal facial tracking; and an Auditory engine converting 1D waveforms into 2D Mel-Spectrograms for synthetic frequency classification. By intercepting live WebRTC streams via a zero-dependency DOM injection protocol, the architecture bypasses traditional file-download bottlenecks. Utilizing a Weighted Confidence Algorithm for decision-level fusion, the system achieves a 97.8% ensemble accuracy and gracefully degrades in the absence of specific data streams, analyzing 5-second media buffers with a maximum latency of 2.1 seconds. This survey demonstrates that decoupled, parallel modality processing offers a vastly superior, fault-tolerant framework for commercial deepfake interception compared to traditional synchronous models.