
Semantic Similarity for Zero-Shot Hate Speech Detection in Low-Resource Languages
DOI:
https://doi.org/10.65521/ijaece.v15i1S.1343Keywords:
Abstract
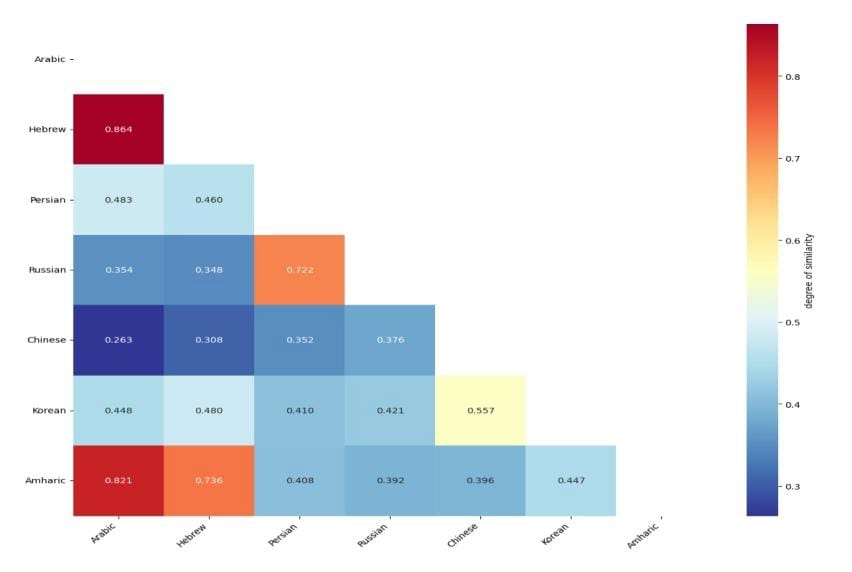
This study investigates the role of semantic similarity in improving zero-shot and cross-lingual hate speech detection across several low-resource and typologically diverse languages, including Arabic, Hebrew, Persian, Russian, Chinese, Korean, and Amharic. A novel framework is proposed that clusters languages based on semantic and genealogical similarity using multilingual sentence embeddings derived from the XLM-R model. Each cluster was used to fine-tune the multilingual mDeBERTa-v3-base-mnli-xnli model, which was then evaluated in zero-shot settings on unseen languages within and across clusters. The results show that zero-shot transfer is highly influenced by linguistic proximity: models trained on Semitic languages (Arabic–Hebrew–Amharic) achieved strong zero-shot performance with F1 scores between 0.80 and 0.86 on unseen languages, while the Indo-European cluster (Russian–Persian) yielded competitive results (F1 ≈ 0.71–0.80). Training on typologically distant East Asian languages (Chinese–Korean) also demonstrated effective zero-shot generalization (F1 ≈ 0.75). Moreover, incorporating a newly developed Yemeni Arabic hate speech dataset enhanced Arabic performance and improved zero-shot transfer to related languages. These findings highlight the significance of semantic similarity in facilitating cross-lingual generalization and offer a scalable strategy for multilingual hate speech detection in low-resource settings.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.