
Enhancing Arabic Web Article Classification through Label Noise Reduction and Class-Balanced Training
DOI:
https://doi.org/10.65521/ijaece.v15i1S.1347Keywords:
Abstract
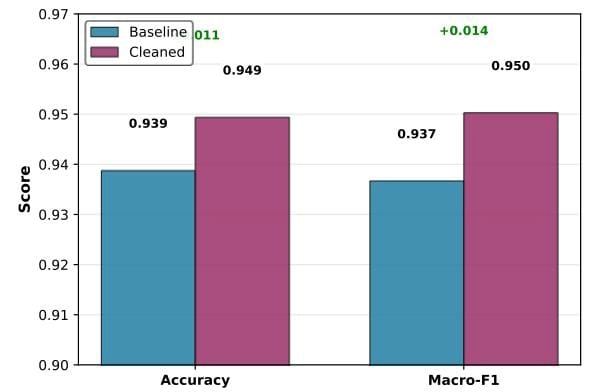
We present an applied, data-centric study on improving large-scale Arabic web-article classification by detecting and correcting label noise in a 451K-article corpus. Building on a practical AraBERTv02 fine-tuned baseline, we develop an automated noise-detection and relabelling pipeline that combines model confidence, MC-dropout ensemble agreement, and probabilistic flagging inspired by Confident Learning. Using stratified reduced experiments (Train=50k, Val=5k, Test=5k) we automatically relabelled 880 training examples and retrained the classifier. On the held-out 5k test set the cleaned model improved Macro-F1 from 0.9367 (baseline) to 0.9503, a statistically significant gain confirmed by McNemar’s test (p ≈ 1.9e-5) and bootstrap 95% CI for Δ Macro-F1 = [0.0082, 0.0190]. We analyse per-class gains, error modes, and cost trade-offs of automated relabelling versus manual review, and release anonymized preprocessing scripts and experiment artifacts to support reproducibility. Our results show that conservative automatic relabelling — judiciously combined with uncertainty estimation — can yield meaningful, reproducible improvements for large-scale Arabic article classification.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.