
Auto-Labeling Of Medical Arabic Texts
DOI:
https://doi.org/10.65521/ijaece.v15i1S.1339Keywords:
Abstract
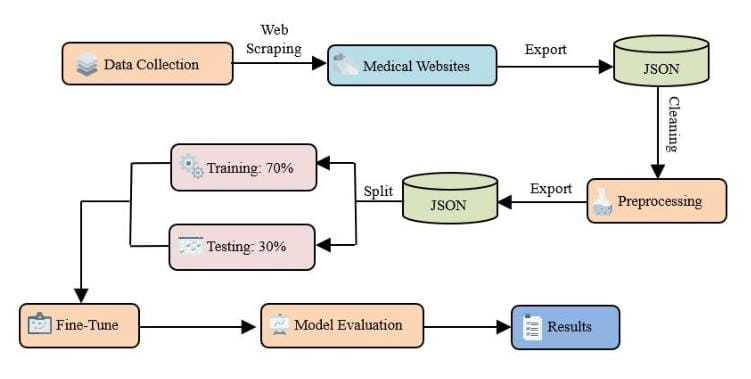
Title generation is a specialized area of natural language processing (NLP), and most studies in this area focus on English, while other languages, such as Arabic, are still in their infancy. Recent research has focused on developing title generation systems for Arabic texts, which can be challenging given the nature of the Arabic language and of datasets. Using artificial intelligence (AI), titles were created and information from lengthy texts was made easier to obtain. The titles and content of each title from verified websites were compiled into a dataset. The title-generating work was started using the Arabic T5 transformer-based title generation model. Following that, the final model was assessed using assessment techniques such as BERTScore, ROUGE, BLEU, and F-Score. On the BERTScore scale, the suggested model performed well, earning the highest evaluation score of 87, lso the model was evaluated by four independent, expert evaluators, with the arithmetic mean of the evaluations being 7.25/10, indicating good acceptance of the results. In order to improve the model's performance, the researchers propose applying human evaluation, changing the model's structure, and growing the dataset.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.