Semantic Image Segmentation using Deep Learning Models
DOI:
https://doi.org/10.65521/ijacte.v13i2.136Keywords:
Abstract
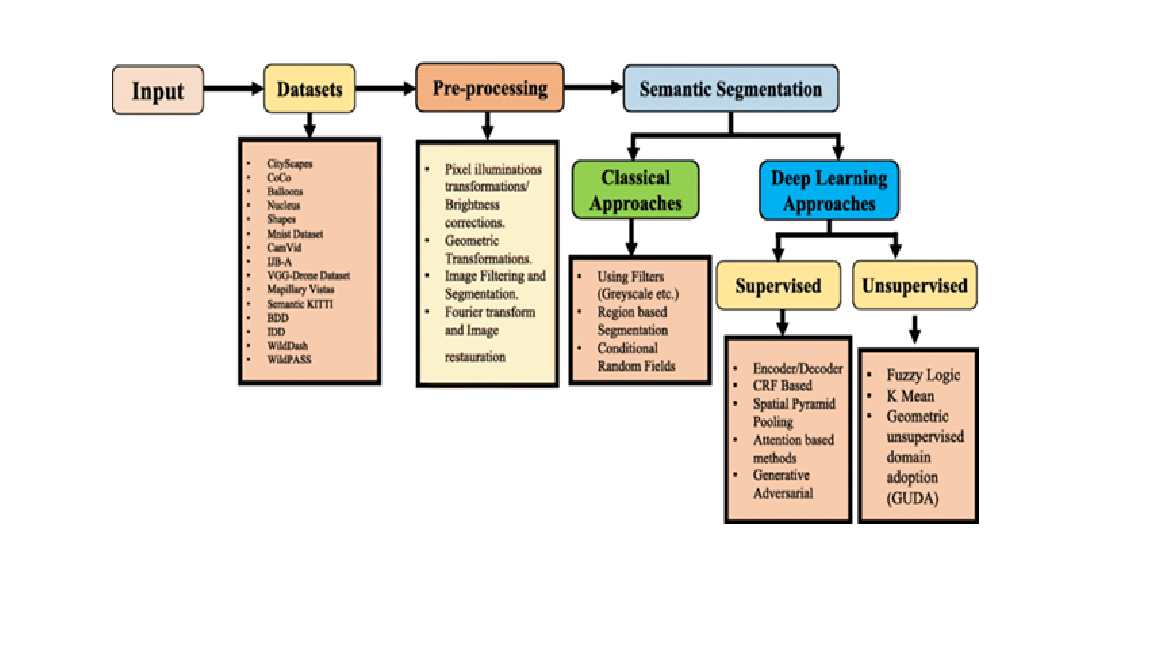
Semantic image segmentation is a fundamental task in computer vision that involves assigning a class label to each pixel in an image, aiming to understand and interpret the visual content at a semantic level. Deep learning models, particularly convolutional neural networks (CNNs), have revolutionized this field, achieving significant advancements over traditional methods. This paper provides an overview of deep learning-based approaches for semantic image segmentation, highlighting key architectures such as Fully Convolutional Networks (FCNs), U-Net, DeepLab, and the use of advanced techniques like transformers and attention mechanisms. We explore various datasets and benchmark evaluation metrics that assess the performance of these models, particularly in domains such as medical image analysis, autonomous driving, and remote sensing. Additionally, we discuss the challenges faced in semantic segmentation, including class imbalance, high computational cost, and the need for large annotated datasets, and propose strategies for overcoming these issues. The integration of active learning techniques and semi-supervised learning in enhancing model performance with minimal labeled data is also covered. Finally, we present future directions, including the integration of multi-modal data and the development of more efficient, lightweight models for real-time applications.