Deep Generative Models for Synthetic Data Generation and Augmentation
DOI:
https://doi.org/10.65521/ijacect.v13i1.61Keywords:
Abstract
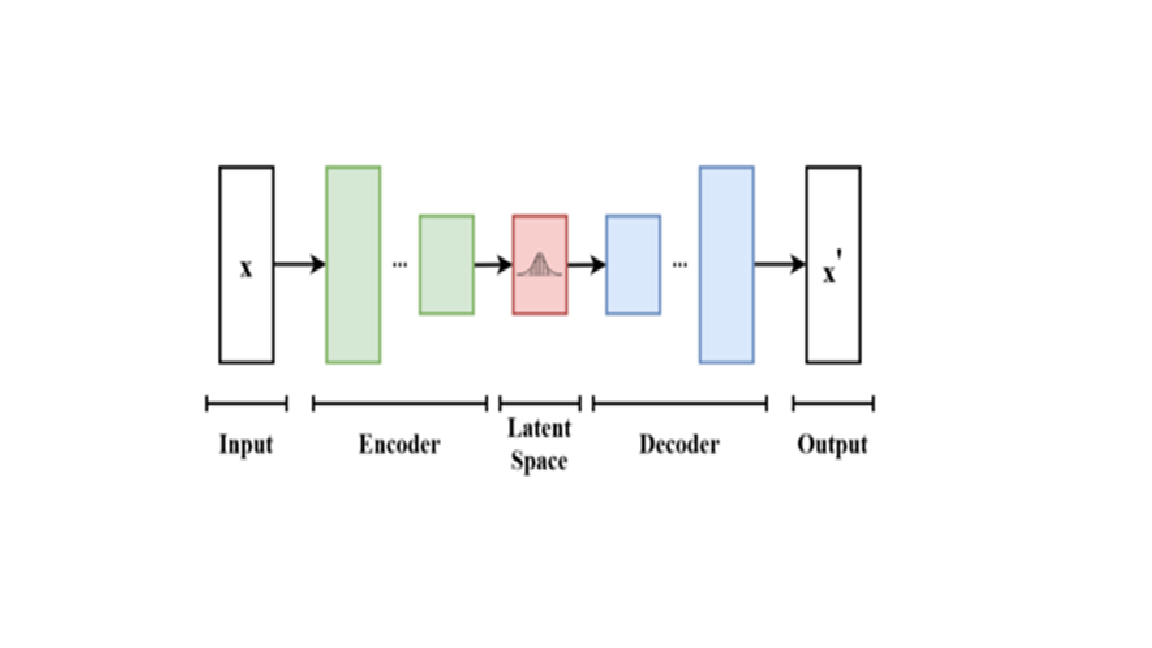
The growing demand for large-scale, high-quality datasets in fields such as machine learning, artificial intelligence, and medical research has prompted the exploration of synthetic data generation techniques. Deep generative models, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and normalizing flows, have shown great promise in generating realistic data across various domains. This paper provides an in-depth review of these models, highlighting their applications in synthetic data generation and augmentation. We discuss the principles, advancements, and challenges associated with deep generative models, including issues such as mode collapse, training instability, and the need for domain-specific adaptations. Furthermore, we explore the role of synthetic data in improving model robustness, enhancing privacy, and addressing data scarcity in sensitive areas like healthcare and autonomous driving. We conclude by outlining future directions for research, emphasizing the integration of generative models with other data augmentation techniques to further advance their applicability and efficiency.