Stylometric Author Identification via CNN-BiLSTM Architecture on Syntactic Text Patterns
Article Sidebar
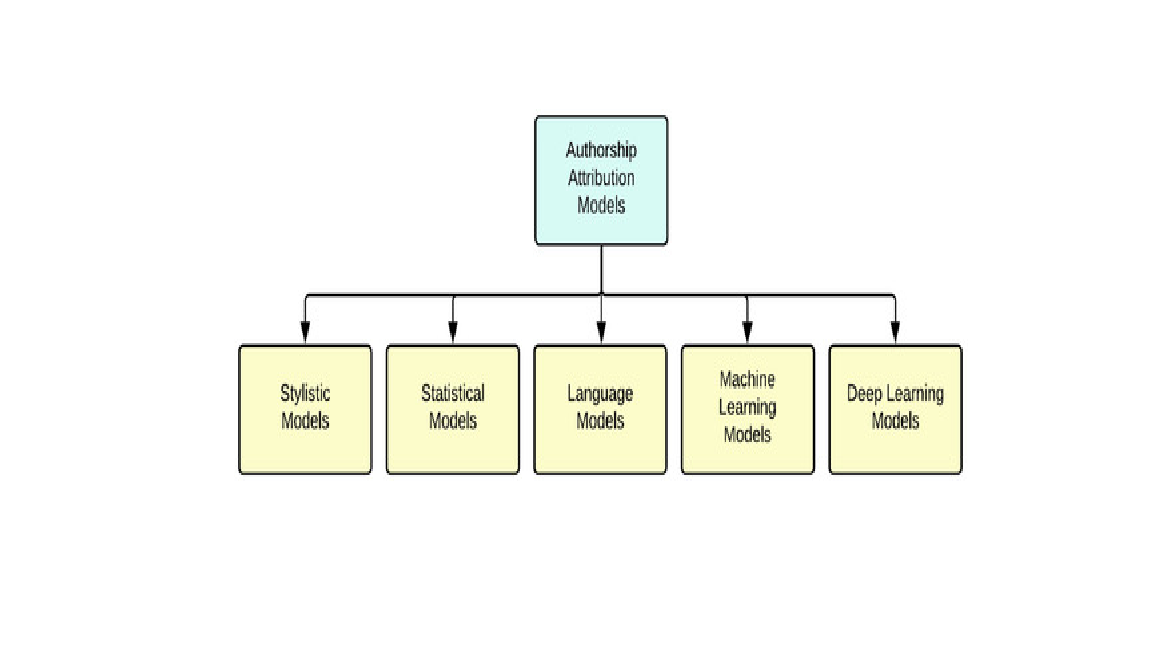
Main Article Content
Abstract
Authorship attribution is a critical task in natural language processing that involves identifying the author of a given text based on writing style, linguistic patterns, and structural features. This research presents a deep learning-based approach combining Convolutional Neural Networks (CNN) and Bidirectional Long Short-Term Memory (BiLSTM) networks to accurately attribute authorship. Using the Reuters-50-50 dataset, we extract syntactic and structural information such as part-of-speech tags, punctuation frequency, and average sentence length, which help capture the unique stylistic traits of individual authors. The text is cleaned, transformed into numerical vectors, and used to train the proposed model. Experimental results demonstrate that the hybrid CNN-BiLSTM architecture achieves high accuracy of 96% in identifying authors from unseen text samples. The model also performs well across other metrics such as precision, recall, and F1-score, showing its robustness and effectiveness in capturing deep textual patterns. This work contributes to the fields of authorship verification, plagiarism detection, and digital forensics, offering a scalable and reliable solution for text-based author identification.