
Towards Forgettable AI
DOI:
https://doi.org/10.65521/ijacect.v14i3s.1604Keywords:
Abstract
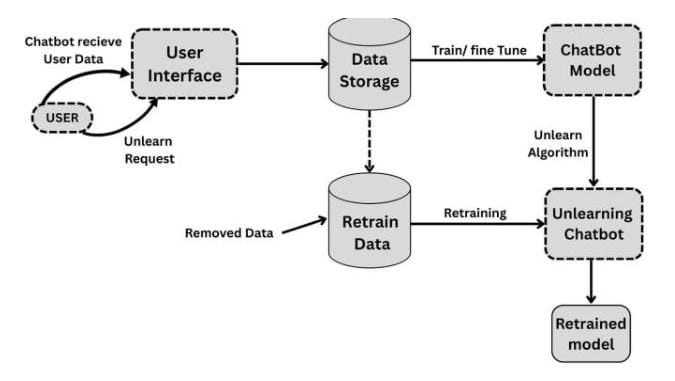
This paper reviews the growing field of Machine Unlearning (MU), a discipline that supports modern privacy regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), both of which provide users the right to have their data removed. Drawing on insights from recent research, the work presents an overview of MU principles, algorithms, and their implementation within artificial intelligence (AI) chatbot systems. The central problem addressed is how to efficiently remove the impact of specific data samples from trained models without retraining them entirely. Current literature presents two main categories: exact unlearning, which ensures complete data removal, and approximate unlearning, which offers faster and more practical performance. The techniques are broadly classified into data-based, model-based, and hybrid approaches. Federated Unlearning (FU), an extension of MU for distributed systems, introduces further complexities such as user participation and privacy leakage. Verification strategies, including adversarial evaluations like Membership Inference Attacks (MIA), are critical to validating that the system truly forgets deleted information. This paper concludes with recommendations for incorporating MU into conversational AI to promote transparency, privacy, and responsible data handling.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.