
Multi Group classification based on Arabic
DOI:
https://doi.org/10.65521/ijaece.v15i1S.1340Keywords:
Abstract
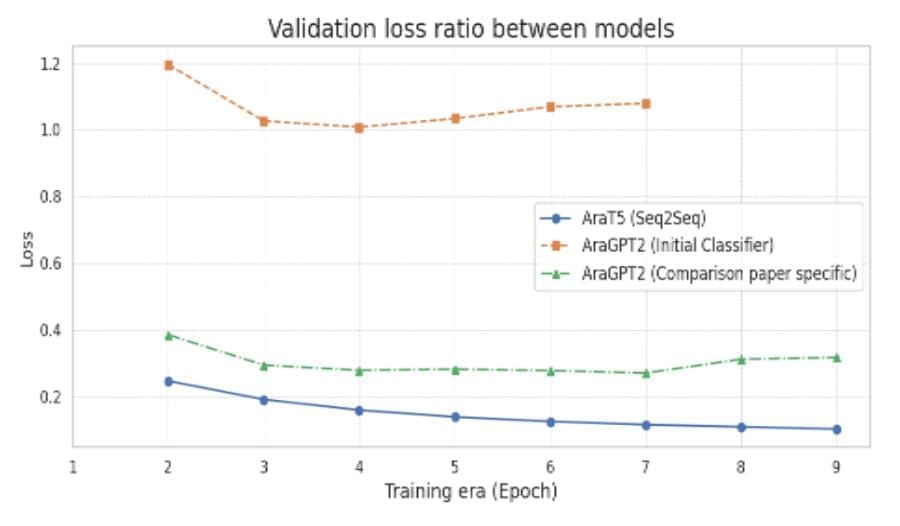
Hierarchical text classification represents a significant and critical challenge in the field of Arabic natural language processing. This challenge is further complicated by the language's morphological richness and the scarcity of large-scale, structured datasets. This paper presents a comprehensive comparative study of two modern approaches to fine-tuning this task: a generative text-to-text approach using the AraT5 model, and a direct classification approach using the AraGPT-2 model. These models were evaluated on a large, specially collected dataset comprising over 75,000 articles distributed across 600 subcategories, as well as a smaller benchmark dataset compared to the previous literature. Experimental results demonstrated that the generative AraT5 model achieved superior performance and hierarchical consistency on this large and complex dataset. Furthermore, our improved AraGPT-2 model, enhanced with advanced regularization techniques, significantly outperformed the current literature benchmark on the compared dataset, achieving a hierarchical F1 score of 93.54%. The results indicate that, while both approaches are effective, the generative approach demonstrates a clear advantage in dealing with a fuzzy classification space. This work establishes new performance benchmarks and provides critical insights into the impact of fine-tuning strategies and data complexity on the hierarchical classification of Arabic.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.