
From Text to Toxicity: Exploring the Challenges in Marathi Hate Speech Detection
DOI:
https://doi.org/10.65521/ijacte.v15i1S.1318Keywords:
Abstract
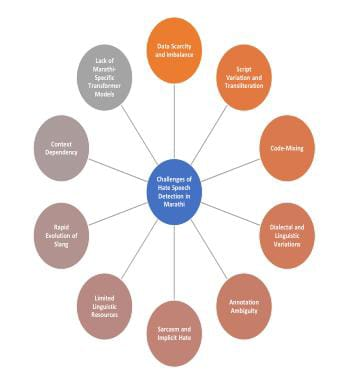
Hate speech on social media has become a serious problem in society. There is a increasing need to create systems that can automatically detect such hateful content. Marathi, an Indo-Aryan language widely spoken in India, remains under-represented in natural language processing research due to limited linguistic resources and annotated datasets. This study focuses on the major challenges faced in detecting hate speech in the Marathi language. Marathi is a low-resource and complex language. It does not have enough large and balanced datasets for proper model training. The presence of code-mixing, transliteration between Devanagari and Roman scripts, and various dialects increases the complexity of text processing. Ambiguity in meaning, sarcasm, and context-dependent expressions make automatic detection more difficult. This paper systematically reviews the challenges in Marathi hate speech detection arising from data scarcity, code-mixing, transliteration, dialectal variation, annotation ambiguity, and context-dependent expressions.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.