Deep Learning and Optimization Approaches in Hardware Efficient CNN Architecture Design using Decoder-Based Low Power Approximate Multiplier and Error Reduced Carry Prediction Approximate Adder for MNIST Dataset Classification: A Review
DOI:
https://doi.org/10.65521/ijacect.v14i2.2746Keywords:
Abstract
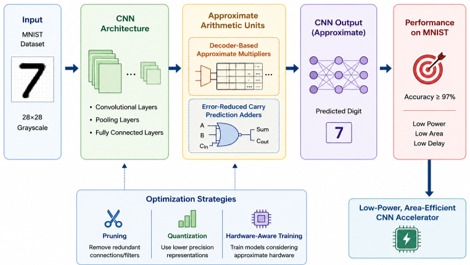
The rapid growth of deep learning applications, especially Convolutional Neural Networks (CNNs), has significantly increased computational complexity and hardware resource requirements. This poses challenges in deploying CNN models on resource-constrained devices such as embedded systems and edge computing platforms. To address these limitations, approximate computing techniques have emerged as a promising solution to enhance hardware efficiency by trading off minimal accuracy loss for significant reductions in power, area, and delay. This paper presents a comprehensive review of deep learning and optimization approaches for hardware-efficient CNN architecture design using decoder-based low-power approximate multipliers and error-reduced carry prediction approximate adders. The study particularly focuses on MNIST dataset classification as a benchmark for evaluating performance. Recent advancements in approximate multiplier architectures, including partial product reduction and compressor-based designs, have demonstrated substantial energy savings while maintaining classification accuracy. Additionally, optimized adder designs contribute to reducing propagation delay and improving arithmetic efficiency in multiply-accumulate (MAC) units. The review highlights how integrating approximate arithmetic units within CNN architectures enhances performance, reduces power consumption, and improves throughput. Furthermore, the paper discusses trade-offs between accuracy and hardware efficiency, providing insights into future research directions in low-power AI hardware design.