Scalable Distributed Data Mining Framework for Knowledge Discovery in Heterogeneous Big Data
DOI:
https://doi.org/10.65521/ijacect.v14i2.2714Keywords:
Abstract
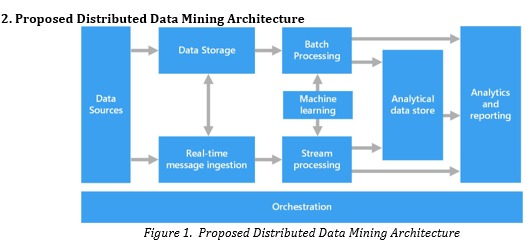
The rapid growth of heterogeneous big data generated from social media, IoT devices, cloud platforms, healthcare systems, financial networks, and enterprise applications has created significant challenges for scalable knowledge discovery and intelligent data analytics. Traditional centralized data mining approaches often struggle to handle the volume, velocity, variety, and distributed nature of modern large-scale datasets. Distributed data mining frameworks have therefore emerged as an effective solution for scalable processing, parallel computation, and efficient knowledge extraction across geographically distributed environments. This research proposes a scalable distributed data mining framework for knowledge discovery in heterogeneous big data environments. The proposed framework integrates distributed storage systems, parallel data processing architectures, machine learning-based analytics, and intelligent resource allocation mechanisms to improve scalability, computational efficiency, and knowledge extraction capability. The framework utilizes distributed computing technologies such as Hadoop, Spark, and cloud-based architectures to support large-scale heterogeneous data analysis. The study incorporates preprocessing, feature extraction, clustering, classification, and association rule mining techniques within a distributed analytical pipeline. Experimental evaluation demonstrates that the proposed framework significantly improves processing speed, scalability, fault tolerance, and mining accuracy compared to conventional centralized data mining systems. Furthermore, the framework enhances real-time analytical capability and supports adaptive knowledge discovery across structured, semi-structured, and unstructured datasets.