Design and Implementation of an Integrated Distributed Backup and Self-Updating Inference System for Educational Laboratories
DOI:
https://doi.org/10.65521/ijeecs.v15i1S.3037Keywords:
Abstract
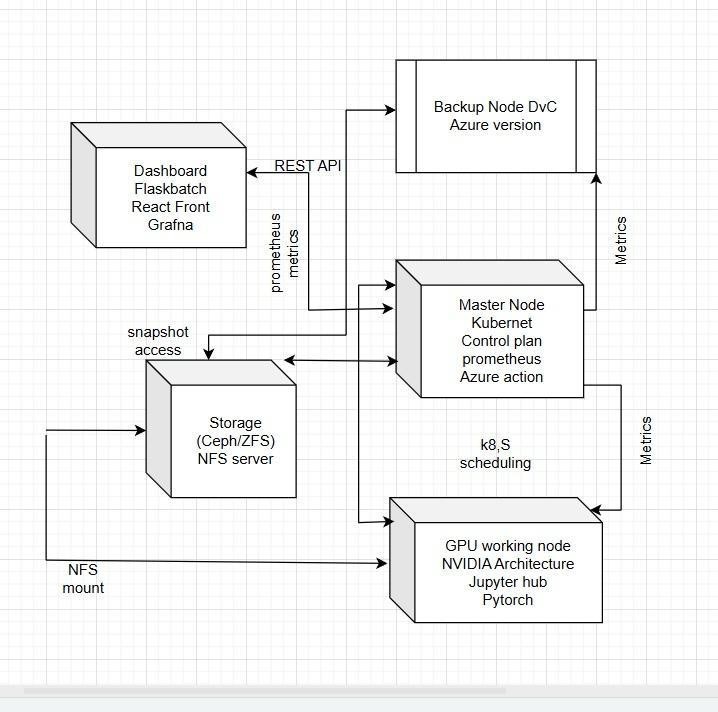
Educational institutions and small-scale research labs face dual challenges: frequent loss of user-generated data (code, datasets, reports) and high costs of cloud-based machine learning (ML) infrastructure. Existing solutions—ranging from consumer cloud backups to enterprise hyperconverged platforms like Nutanix—are either too expensive, too complex, or lack integration between data preservation and intelligent services. This paper presents the design, implementation, and evaluation of a low-cost, open-source system that unifies automated distributed backup with a self-updating edge inference pipeline. Built on recycled hardware using Docker, FastAPI, and ZFS snapshots, our system enables client workstations to back up critical folders while simultaneously feeding labeled data into a retraining loop that automatically upgrades the inference model upon accuracy improvement. We demonstrate successful multi-client operation, versioned restore, real-time prediction, and zero-cloud dependency.