Self Healing Infrastructure System
DOI:
https://doi.org/10.65521/ijeecs.v14i1.190Keywords:
Abstract
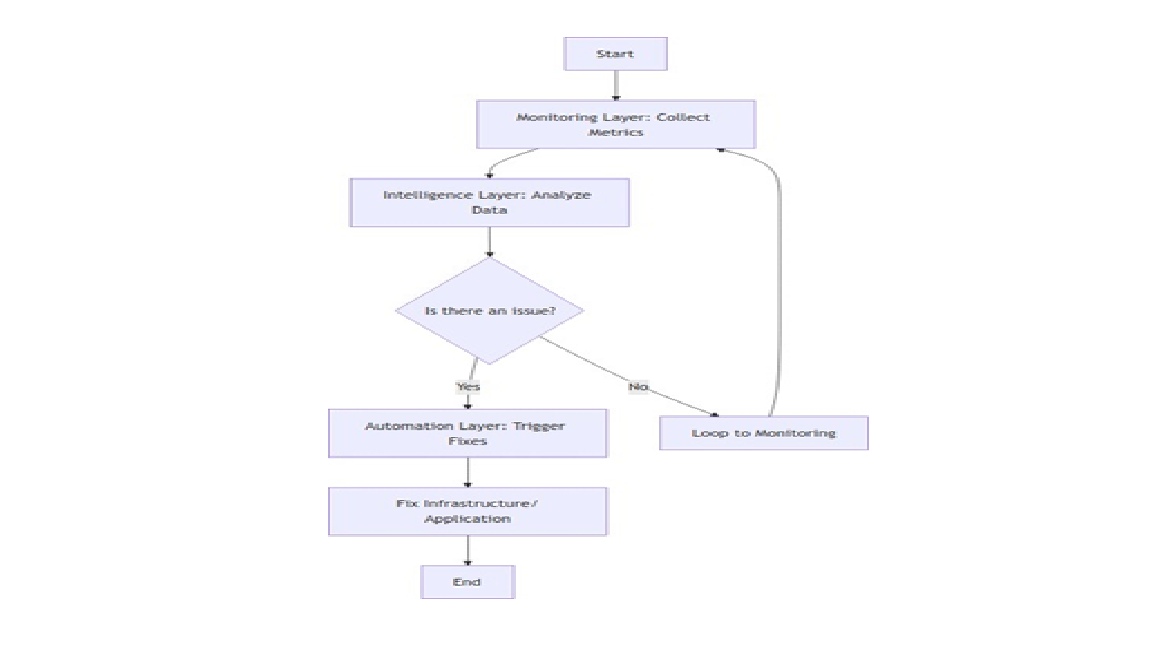
Managing modern IT infrastructure has become increasingly complex with the adoption of containerized applications and distributed architectures. Traditional methods reliant on manual monitoring, fault detection, and recovery are no longer sufficient due to their slow response times, error-prone nature, and increased downtime. The need for 24/7 system availability and unpredictable failures highlights the urgency of more resilient solutions. Advanced tools like Prometheus offer real-time observability, anomaly detection, and system health monitoring, enabling quicker responses. However, traditional approaches lack automated remediation capabilities.
Integrating DevOps practices with ML-driven technologies addresses these gaps. Enhancing tools like Prometheus with self-healing capabilities allows infrastructures to autonomously detect anomalies, diagnose issues, and execute automated recovery workflows. This reduces downtime, optimizes resources, and minimizes manual intervention. This research aims to develop a scalable, robust system ensuring business continuity, reliability, and resilience in dynamic, cloud-native environments, unlocking the potential of autonomous infrastructure management.